
1.「人工知能と学習データ」
人工知能は生まれながらにして人工知能であるわけではない。
できたての人工知能は生まれたての乳幼児と同じくなにも知らない。ただ学習することを知っているのである。つまり、乳幼児が親や周囲から様々なことを学び成長していくように、人工知能は膨大なデータから学習し、人工知能たり得るのである。そして、人工知能が学習をする目的は、何らかの事象を予測することである。人工知能を用いた画像認識では、大量の画像データから学習し、新たに提示された画像が何であるかを予測する。
では、学習するデータが誤っていたり、偏っていたり、不十分であったらどうなるのであろうか。2015年に1つのツイートが話題になった。人工知能を用いて画像認識を行うGoogle Photosで、アフリカ系アメリカ人が「ゴリラ」と判定されたのである。グーグルの画像認識は、インターネット上に投稿された画像と、それに関連付けられたSNSなどの人物情報などを学習データとして用いているといわれている。当然その中には「ゴリラ」の写真も含まれるであろう。またアフリカ系アメリカ人の画像データがそもそも少なかったともいわれている。
この問題は、グーグルの画像認識に限った話ではなく、フェイスブックでも類似の事象が発生している。さらに人工知能の学習データに起因する問題は、画像認識固有の問題ではない。人工知能全般において、学習データに起因する問題は起こり得る。
2.「人工知能が学習するデータとは何か?」
人工知能が学習するデータ、ビッグデータにはどのような特徴があるのであろうか。ビッグデータとは文字通り膨大なデータであるが、西垣(2016)によると、その特徴は、データの「量(Volume)」「多様性(Variety)」「高速処理(Velocity)」である。大量の多様なデータを高速で処理をする。多様性とは、先ほどのグーグルの画像認識で見てみると、画像データやSNSでの人物情報といった多様なデータを有機的につなげ合わせて処理をすることを示している。西垣(2016)は、加えて「全件処理」「質より量」「因果から相関へ」といった分析についての特性を挙げている。
「因果から相関へ」とは、多様なデータがあるのだから1つ1つ因果関係を考えるよりも、関連があるかないか総当たりで機械的に分析していくという考えである。相関とは、一般的に身長が高いほど体重が重いといった関係を示しているが、「身長が伸びれば体重が増える」「体重が増えれば身長が伸びる」といった因果関係を含まない。因果関係よりも相関というのは部分的には正しい。
社会調査などでも、新しい事象に対する調査で探索的に分析を行う場合、「まずは関連があるか相関を見てみよう」ということはよくある。また、人工知能を用いた新薬の開発の様に、まずは人工知能を用いて膨大な組み合わせをシミュレーションしてみるというのも理にかなっているであろう。しかし、データ上、相関があるからといって、実際に関連があるかどうか十分に検証されたわけではない。擬似相関の可能性も残る。擬似相関とは、実際に直接関連がないにもかかわらずあたかも関連があるかのように見える事象で、それらは慎重に検証を行う必要がある場合も多い。そう捉えるとビッグデータやそれを用いた人工知能は「因果から相関へ」というよりも「探索的な仮説の抽出」するものと考えられる。
従来は、ネジなどの品質管理であれ、伝染病流行の要因についての疫学研究であれ、すべてのネジや人を対象とすることはせず、その中から一部を抽出(これをサンプリングという)し、分析することが大半であった。すべてのネジや人の情報を収集することは、時間や費用が膨大になり、また仮に収集したとしても分析することが困難であった。例えばセンシング技術などの進化により、すべてのネジの状態を取得することは容易になった。
しかし、サンプリングした一定数のネジを丁寧に検査するよりも、センサーによる検査は、一部のセンサーの故障等を含めかえって精度が低くなることもある。そうであったとしても、すべて検査したほうがよい、というものがビッグデータ分析における「全件処理」および「質より量」の考え方である。
3.「人工知能は何を学習するのか?」
「全件処理」の「全件」とは何を指すのであろうか。
世論調査などの社会調査には母集団という概念がある。母集団とは、調査の対象が誰であるのかを指し、社会調査は、観測データからこの母集団の性質を明らかにすることを目的としている。一般的な世論調査であれば、世論を形成する市民が母集団である。日本人の政治意識を明らかにしたいという場合、母集団は日本人であろう。社会調査での予測の対象は母集団となる。つまり、社会調査における母集団とは人工知能における予測対象ということができる。
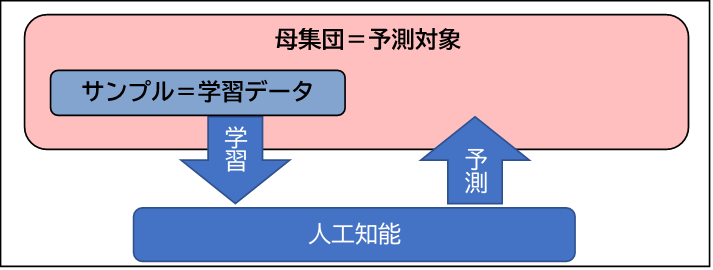 図 社会調査の視点から見た人工知能の学習と予測の関係
図 社会調査の視点から見た人工知能の学習と予測の関係
人工知能が学習するデータは、「全件処理」というだけあり、社会調査の悉皆調査のデータをイメージしてしまいがちである。
しかしそうではない。人工知能が学習するデータは、社会調査でのサンプルに相当する。このサンプルに含まれる人の数をサンプルサイズというが、人工知能が学習するデータはサンプルサイズが非常に大きいということが先ほどの特徴の1つである。そして、「全件処理」の「全件」とは、場合によっては、「母集団の中の特定集団」=「母集団」であることはあるかもしれないが、基本的には「母集団の中の特定集団」への悉皆調査と捉えることが適切であろう。
ここで、社会調査では、サンプリングは可能な限り無作為にする(ランダム・サンプリング)という原則がある。調査対象者は母集団の縮図である必要がある。そこに何らかの偏り(サンプリング・バイアス)があると、得られたデータから母集団の特性を正確に予測することは困難である。一方で、完全なランダム・サンプリングには母集団のリストが必要であるなど、実際に行うことが困難なことも多く、実際には何らかの形で有意抽出することが多い。
例えば、昨今、インターネットを用いた調査(いわゆるネット調査)が非常に多い。これはインターネットを利用していない人も含む市民を母集団とした世論調査では不適切な手法であろう。またネット調査の多くは調査会社のモニターを対象としており、世間一般と比べて学生や主婦(夫)、また比較的若年層の比率が高く(労働政策研究・研修機構, 2005)、偏っているといわざるを得ない。
さらに、社会調査においてサンプリングされた調査対象者の人数と、実際の分析に用いることのできるサンプルサイズが異なることがある。社会調査では何らかの形で調査への協力を依頼することになるが、必ずしも調査対象者の全員が回答してくれるわけではない。
個人情報の流出を恐れて回答を拒否したり、単純に回答する余裕がないため回答しなかったり、理由はさまざまである。この「実際に調査に協力してくれた人数」(分析に用いることのできるサンプルサイズ)÷「調査を依頼した人数」(調査対象者の人数)のことを回収率という。この回収率はランダム・サンプリングでは非常に重要である。回収率が低い場合、特定の傾向のある人が回答していない可能性があり、ランダム・サンプリングしたにもかかわらず、結果として有意抽出と変わらない可能性が出てきてしまう。
では、人工知能が学習するデータにサンプリング・バイアスはないのであろうか。あらためて、先ほどの人工知能が学習に用いるビッグデータの「全件処理」の「全件」について考えてみよう。人工知能が学習するデータが社会調査におけるサンプルであるとすると、この「全件」はサンプリングされた調査対象者の全員のデータと捉えることが適切であろう。つまり社会調査で言うところの回収率が100パーセントであるというだけである。
このようにとらえると、人工知能が学習するデータでもっとも重要となることは、その学習データが予測対象となる母集団に対して適切であるのかということであろう。
4.「人工知能の学習データと予測対象」

Amazonでの購買履歴は、Amazonの利用者を「学習データ」としたものとして、Amazonの利用者に対してAmazon内の商品を推薦するような場合、予測対象の母集団はAmazonの利用者であり、「学習データ=母集団」としてもよいかもしれない。このように人工知能が学習するデータが母集団という限られた状況下であれば問題ではない。
非常に限定的な目的で利用される人工知能であれば、「学習データ=母集団」である可能性はある。しかし、Amazonでよく売れている商品をコンビニに置けば売れるかというと必ずしもそうではない。Amazonでよく売れている商品というときの「学習データ」はAmazon利用者のものである。しかし、コンビニ利用者、つまり予測対象の「母集団」は必ずしもAmazon利用者ではない。このように「学習データ」と予測対象の「母集団」とはしばしば一致しない。
このとき、「学習データ」と予測対象は、往々にしてそれぞれ別の傾向がある。
例えば、スマートフォンの位置情報のデータを考えた場合、そこに含まれない人はスマートフォンを持っていない人(高齢者で比率が高い)や位置情報の取得に同意していない人(情報リテラシーが高い人や個人情報にセンシティブな人)である。仮に契約情報等と紐づけて高齢者のみに限定したスマートフォンの位置情報のデータを学習したとしても、高齢者全体の移動情報とするには危険を伴う。高齢者でスマートフォンを持っている人はアクティブシニアともよばれる人が多く、持っていない人に比べて活動的な人に偏っている。
つまり高齢者のスマートフォンの移動情報をもとにして高齢者の運動が十分か否かを議論したところで、このデータでは実際の高齢者よりも移動距離が長い可能性が高い。このように学習データに偏りがある場合、母集団を予測することは危険である。
とはいえこのような学習データの偏りは必ずしも自明であるとも限らない。難しいことに、予測がつかないような偏りがある可能性もある。したがって、これを仮説として、別途検証をする必要があるであろう。またビジネスとしてトライアル・アンド・エラーを繰り返す前提であれば問題でないかもしれない。
しかし、詳細な検証もせずに高齢者の動線であるとしてスロープを設置するといった公共の問題や長期間において是正されにくい問題においては、必ずしも適切な手法とは言えない。このような予測対象の母集団に対して学習データが不適切であるような状態は、社会調査においてもしばしばみられる。ネット調査のデータをもって日本人の行動を予測したり、特定の大学の特定の授業に出席している学生に対する調査結果を一般的な大学生の傾向のように議論したりしていることもある。
5.「人工知能は誰から学習し、誰を予測するのか」
人工知能およびビッグデータにおいては、予測対象の母集団に対する学習データが不適切である問題は、以下の2つの場合、さらに大きな問題となる。1つは、人工知能、もしくはビッグデータがネットワーク化された場合である。簡単に言えば、単独の人工知能やビッグデータではなく、複数の人工知能やビッグデータがインターネット等を通じて互いに参照・連携するような場合である。そのような状況下では、学習データ同士でサンプルが異なる。さらに、それらの多様な学習データの多くが予測対象の母集団に対して適切であることは困難になるであろう。その結果、ネットワーク化人工知能の予測の精度に問題が生じる可能性がある。
もう1つは、特定の文化圏のデータを学習した人工知能を、他の文化圏に適用しようとした場合である。例えば、アメリカ人の食事のデータから学習した人工知能があったとしよう。その人工知能はその日の夕食を提案し、不足している食材を注文してくれる。それを日本に適用しようとした場合、予測対象の「母集団」は日本人となる。そもそも使われない可能性は否定できないが、一定の人がその人工知能の提案を受け入れた場合、アメリカの比較的高カロリーな食事が日本で増加するなど何らかのコンフリクトが発生する可能性がある。これは文化圏に限った話ではないが、予測対象の母集団に何らかの影響を与える可能性は否定できない。
このような人工知能が学習するデータが予測対象となる母集団にたいして不適切であるという問題は、学習するデータを予測対象の「母集団」へと拡大しつつ学習し続ければ、そのうち解消するかもしれない。
しかし、「完全なもの」は現実的ではなく、「一般に許容されるレベル」に達するまで、人々は耐えられるのか。もしくは、問題に気づかない間に、予測対象に対して不適切な学習データに基づく人工知能が徐々に入ってきているかもしれない。

参考文献
西垣通(2016)『ビッグデータと人工知能』中公新書
労働政策研究・研修機構(2005)インターネット調査は社会調査に利用できるか-実験調査による検証結果-, 『労働政策研究報告書2005』, No.17.












